Testing retention of historical PIs in Camunda 8.8

Summary:
With Camunda 8.8, a new unified Camunda Exporter is introduced that directly populates data records consumable by read APIs on the secondary storage. This significantly reduces the time until eventually consistent data becomes available on Get and Search APIs. It also removes unnecessary duplication across multiple indices due to the previous architecture.
This architectural change prompted us to re-run the retention tests to compare PI retention in historical indexes under the same conditions as Camunda 8.7.
The historical data refers to exported data from configured exporters, such as records of completed process instances, tasks, and events that are no longer part of the active (runtime) state but are retained for analysis, auditing, or reporting.
The goal of this experiment is to compare the amount of PIs that we can retain in historical data between Camunda 8.7 and 8.8 running with the same hardware.
Chaos experiment
Expected Outcomes
We expect significant retention improvements for the same hardware with the change to harmonized indexes, which reduce the duplication of similar data.
Setup
The experiment consists of using a realistic benchmark with our Camunda load tests project running on its own Kubernetes cluster. It uses a realistic process containing a mix of BPMN symbols such as tasks, events, and call activities, including subprocesses.
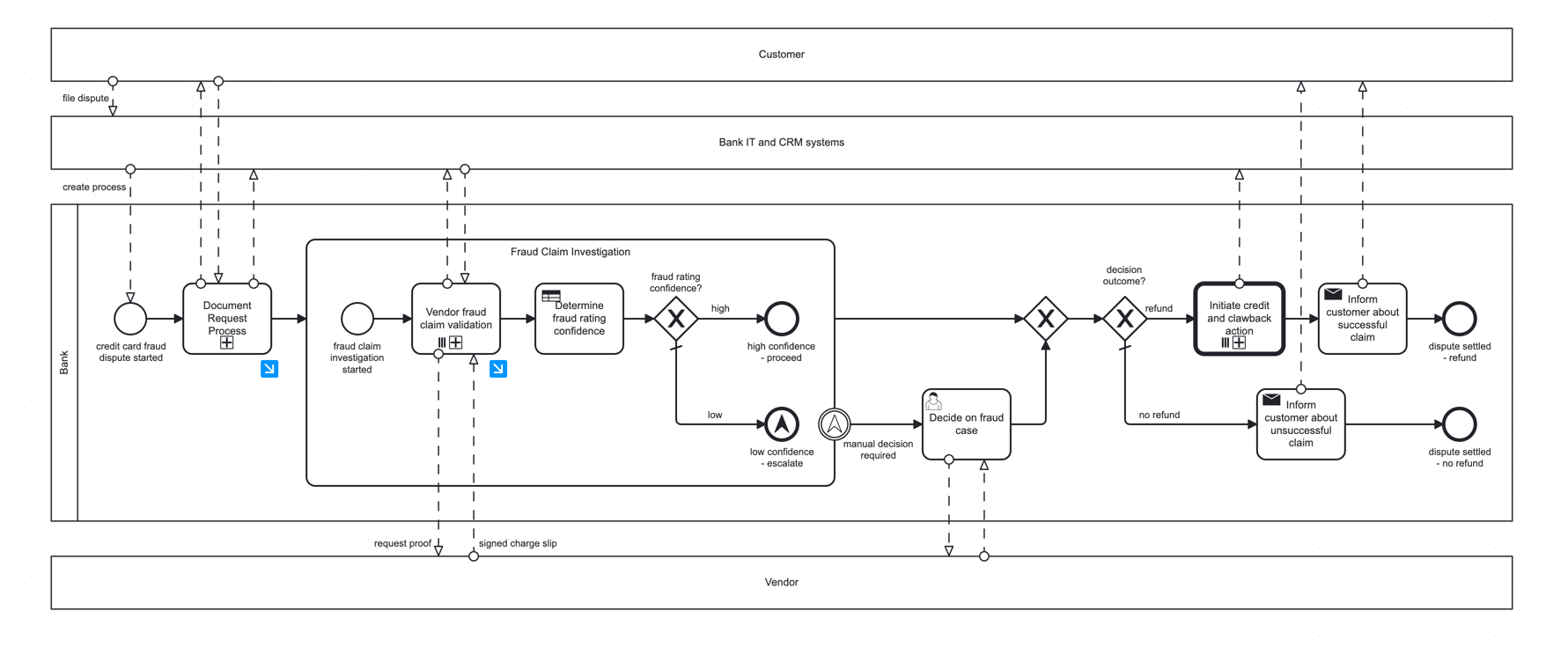
For this experiment, we used a base size 1x cluster consisting of the standard 3 brokers, 3 partitions, a replication factor of 3, and 3 ES pods, each with a disk size of 32GB, for a total of 96GB of storage in ES.
Our goal was to run the cluster at maximum sustained load until exporting slowed and backpressure appeared. We treated that point as the Elasticsearch "watermark" — the threshold where exporting becomes the bottleneck for the cluster. Once we reached this point, we note the disks usage, stopped creating new PIs and counted how many had been archived in the historical indices. That count represents the retention capacity for the given ES disks under maximum sustained load.
Experiment
The experiment involved using the realistic benchmarks and maintaining a stable rate of 5 PI/s (previously determined in other experiments), waiting several hours until backpressure was observed.
After a few hours, backpressure began to build up, reaching single-digit percentage points. Grafana metrics confirmed that the backpressure resulted from a backlog of unexported records.
The experiment was conducted twice to ensure the results were consistent.
Results
The PI/s completion rate remained relatively stable, even as backpressure started to build. The rate stabilized between 4 and 5 PI/s.
Disk usage after backpressure began:
| First run | Second run | |
|---|---|---|
| ES disk 1 | 74% | 74% |
| ES disk 2 | 61% | 72% |
| ES disk 3 | 55% | 67% |
| Average | 63.3% | 71% |
Number of completed historical PI/s:
- First run: 223,000 PIs
- Second run: 255,000 PIs
As we approached 70% disk usage, we noticed some impact on performance resulting of backpressure from exporting. In previous tests with version 8.7, we observed similar backpressure onset between 70% and 80% disk usage.
Given that backpressure can occur earlier than expected, we decided to lower the threshold for automatically increasing disk sizes in the ES PVCs in SaaS (this happens in increments of 16GB). This threshold was reduced from 80% to 70%.
Moreover, when comparing these results to the retention with version 8.7, we observed a significant improvement in retention. This enhancement is attributed to the harmonized indexes and the elimination of duplicate document storage. In version 8.7, for the base 1x cluster with identical disk sizes in ES, the retention was around 75,000 PIs in historical indices. In contrast, we achieved 223,000 and 255,000 in this experiment, representing a 218% increase or 3.18 times larger retention, based on the average of both numbers.
Comparing the retention numbers of both versions we get:
| Cluster size | 1x | 2x | 3x | 4x |
|---|---|---|---|---|
| Camunda 8.7 | 75k | 150k | 225k | 300k |
| Camunda 8.8 | 239k | 478k | 717k | 956k |
Following these results, we updated the retention values in version 8.8. This was done conservatively (we rounded down to 200k for the base configuration), considering the high variability of process models. The intention is to provide a general representation of an average process, establishing standard metrics for performance comparison across Camunda versions.
Participants
- @rodrigo